Course Signals has now been used by 24,000 students at various schools since its introduction in 2007, including about a fifth of Purdue's undergraduates in recent years. It has been shown to increase the number of students earning A's and B's and lower the number of D's and F's, and it significantly raises the chances that students will stick with college for an additional year, from 83% to 97%.
This is one early real-world application of the new and rapidly expanding fields of research called learning analytics and educational data mining.
When students use software as part of the learning process, whether in online or blended courses or doing their own research, they generate massive amounts of data. Scholars are running large-scale experiments using this data to improve teaching; to help students stay motivated and succeed in college; and even to learn more about the brain and the process of learning itself.
But with all this potential comes serious concerns. Facebook caused a furor over the past couple of weeks when the company's lead scientist published a research paper indicating that the social network had tinkered with the news feeds of hundreds of thousands of people in an experiment to see whether their emotions could be influenced.
As unsettling as that may have been, users of a recreational social network are free to click away or delete their accounts at any time. College students, on the other hand, are committed. Earning a degree is crucial to their future success, and requires a significant investment of time and money.
So academics are scrambling to come up with rules and procedures for gathering and using student data--and manipulating student behavior.
"This is a huge opportunity for science, but it also brings very large ethical puzzles," says Dr. Mitchell Stevens, director of digital research and planning at Stanford University's Graduate School of Education. "We are at an unprecedented moment in the history of the human sciences, in which massive streams of information about human activity are produced continuously through online interaction."
Experts say the ethical considerations are lagging behind the practice. "There's a ton of research being done...[yet] if you do a search on ethics and analytics I think you'll get literally seven or eight articles," says Pistilli, who is the author of one of them.
Large Ethical Puzzles
In June, Stevens helped convene a gathering to produce a set of guidelines for this research. The Asilomar Convention was in the spirit of the Belmont Report of 1979, which created the rules in use today to evaluate research involving human subjects.
But the existing human-subject rules fit the new data-driven world "only awkwardly," Stevens says.
Take the most basic principle: informed consent. It says that research subjects should be notified in advance of the nature and purposes of an experiment and be able to choose whether to participate.
But what does informed consent really mean when data collection occurs invisibly, done along with an action like turning in your homework?
Another catch: Often, scientists can't or don't want to specify the purposes of an experiment in advance, since they identify important patterns only after collecting a bunch of data.
Yet another set of concerns arises because a lot of the new educational data collection is proprietary. Companies like Pearson, Blackboard and Coursera each have information on millions of learners.
"This is not a new problem for science," Stevens says, pointing to pharmaceutical and medical research. "But it is a new fact in the field of education research."
A fact that raises big questions: Who owns this data? The student, the institution, the company or some combination? Who gets to decide what is done in whose best interest?
Asilomar came up with a set of broad principles that include "openness," "justice," and "beneficence." The final one is "continuous consideration," which, essentially, acknowledges that ethics remain a moving target in these situations.
'Stereotype Threat' And The 'Pygmalion Effect'
The field of learning analytics isn't just about advancing the understanding of learning. It's also being applied in efforts to try to influence and predict student behavior.
It's here that the ethical rubber really meets the road.
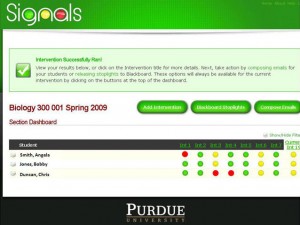
With the Course Signals project, for example, an algorithm flags a certain group of students as being likely to struggle. The information it draws on includes a demographic profile of the student: his or her age, whether they live on campus, and how many credits they've attempted or already earned in college. Depending on the way that prediction is communicated to teachers and students, it could have troubling implications.
A big one would be if the predictions unduly influenced teachers' perceptions of their students.
A body of research going back decades confirms that, if teachers are informed that students are gifted, the students will produce better outcomes, regardless of whether the students really are gifted. It's called the Pygmalion Effect.
"One of the worst possibilities is that we stereotype students," says Justin Reich, who does learning analytics research for the MOOC platform HarvardX. "Any day is the day a kid could turn things around."
And what about the impact of this information on the students themselves?
Research on "stereotype threat" shows that merely being reminded of one's minority status can be enough to depress test performance. Does telling them they have been "red flagged" make them more likely to fail or give up?
In some courses using Course Signals, students do, in fact, tend to withdraw earlier than they otherwise would. "The self-fulfilling prophecy is a concern for a lot of folks," Pistilli says.
Most of these conversations are, for now, hypothetical. Learning analytics has yet to demonstrate its big beneficial breakthrough, its "penicillin," in the words of Reich. Nor has there been a big ethical failure to creep lots of people out.

 When students at Purdue University are reading their homework assignments, sometimes the assignments are reading them too.
When students at Purdue University are reading their homework assignments, sometimes the assignments are reading them too.